In the context of this document, biomedical researchers are the intended audience of ERuDIte and the TCC Web Portal, and consequently, they will be addressed as users or learners.
As a research initiative itself, ERuDIte aims to:
- Identify, store and synthesize large volumes of relevant educational resources in a scalable fashion
- Maintain a schema that aligns with other resource collection initiatives to promote data sharing
- Serve high-quality, up-to-date educational content to the biomedical community (and research community at large) that not only teaches Data Science concepts but also supports the practical application of such concepts into specific analysis tasks
- Aid learners in navigating the vast number of resources pertaining to Data Science through semi-automatic tagging and prerequisite identification
- Provide an individualized learning path through recommendations tailored to learners’ interests, experience, and progress over time
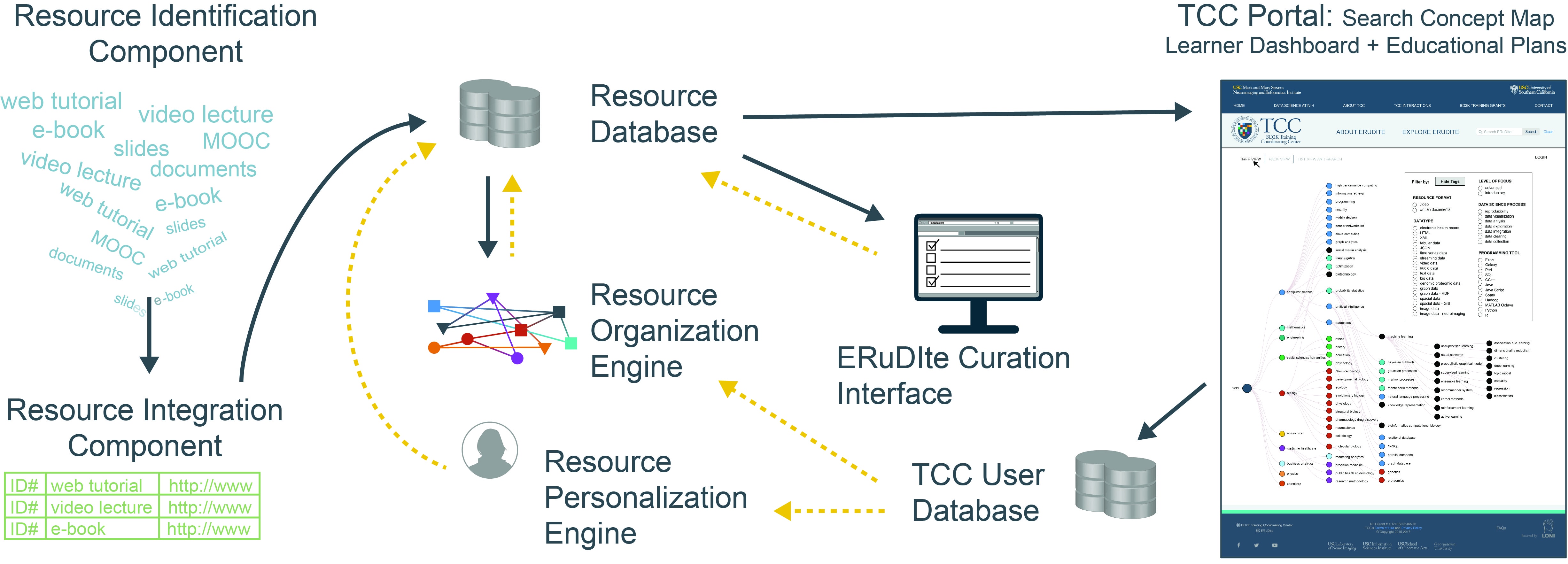
To accomplish these objectives, ERuDIte has multiple components responsible for the resource to ERuDIte to TCC Web Portal pipeline. We illustrate the pipeline below:
- Resource Identification Component: collects links to relevant resources, gathers any available data for the resources, and detects resource quality
- Resource Integration Component: unifies data from heterogeneous resources and conforms them to a standard schema
- Resource Database: stores resource data, making it available for the Resource Organization Engine, Curation Interface, TCC Web Portal, and Resource Personalization Engine
- Resource Organization Engine: automatically assigns tags, identifies prerequisites, and evaluates resource depth and uses curator data from the Curation Interface and user data TCC User Database to improve its algorithms
- Curation Interface: tool for curators to validate organization data and assess resource quality
- TCC Web Portal: presents ERuDIte data and collects learner activity and progress.
- TCC User Database: stores user data, including (but not limited to) learner profile data and usage activity, and informs the Resource Personalization Engine and the Resource Organization Engine
- Resource Personalization Engine: synthesizes user activity, resource tags and prerequisites, and resource similarity measurements to recommend resources to learners
Unified Schema Standard and BioSchemas Exchange
ERuDIte has a schema that allows for data integration across resources and for data exchange between collection initiatives.
The schema of the Resource Database captures the Data Science Learning Resource domain, providing a template of
the data that the Resource Identification Component uses to describe each resource and to enable faceted search
(or elastic search). In developing the schema, we collected and reviewed existing standards: Dublin Core, Learning
Resource Metadata Initiative (LRMI), IEEE’s Learning Object Metadata (LOM), eXchanging Course Related Information (XCRI),
XML Schema Definition (XSD), Metadata for Learning Opportunities(MLO), and Schema.org. Furthermore, we collaborated
with BioSchemas, a European initiative that includes eight organizations that focuses on the development of a cross- institution
metadata standard for educational resources, to design and implement a metadata standard that optimizes data exchange across
many resource collection and development initiatives. This collaboration resulted in a standard that builds heavily on the
one established by Schema.org, a common standard used by many different educational content providers, including
Coursera and Udacity, two major MOOC platforms.
Curation Interface
Curators use the Curation Interface to evaluate resource quality and to validate resource organizational data, which helps to improve resource collection targets and organizational algorithms.
The Resource Organization Engine utilizes algorithms from Machine Learning, Information Retrieval and Natural Language Processing to
automatically provide initial tag assignments, prerequisites, and depth levels. To ensure that the organizational data is correct, the
Curation Interface introduces human validation to the ERuDIte system. Validation not only guarantees that the resource organizational
data on the TCC Web Portal are correct but also provides ground truth data that will improve the algorithms used by the Resource
Organization Engine. Furthermore, curators give the final signoff on whether or not a resource should appear on the TCC website,
providing feedback to the Resource Identification Component on where it should (or should not) look for content.
Knowledge Maps
View the Knowledge Maps here.
The Knowledge Map provides a structure for understanding the relationship between concepts in Data Science knowledge. It also illustrates how resources relate to each other based on the concepts they do or do not share.
Knowledge Maps provide interfaces for navigating the resource index in ERuDIte based on concepts and topics in Data Science. There are two types of maps available: topic and cluster. The cluster map conveys how resources are related to each other based on their topics, which are discovered and assigned automatically. In the cluster map, resources that are closer to each other are more similar than those that are further away. The topic map provides a visual interface to explore and filter the resources in ERuDIte by combinations of their concept tags, which are assigned from the Data Science Education Ontology. This map illustrates how resources relate to each other based on the concepts they do or do not share, and it provides an interactive exploration through a hierarchy of concepts in the Field dimension, allowing learners to see parent-child and sibling relationships between study areas.
The Data Science Education Ontology (DSEO) that powers the topic map consists of six semi-orthogonal dimensions and was constructed with automatic resource classification in mind. In fact, the Resource Organization Engine uses the DSEO’s vocabulary and relationships to perform automated resource tagging, and the Resource Personalization Engine utilizes the tags for recommendation. In addition, the concepts of the topic map form the facets for faceted search in ElasticSearch (which can been seen by typing any term into the search box at the top of the page), allowing learners to expand and narrow search results based on broader and narrower concepts in each knowledge dimension. The dimensions of DSEO are:
1. Field – the field of study
2. Programming Tool – the programming tool used or taught
3. Resource Format – how a resource is presented
4. Level of Focus – the depth of pedagogical coverage
5. Datatype – the types of data addressed
6. Data Science Process - the steps in a data science project
Prerequisites Map (UPCOMING)
The Prerequisites Map establishes concept and individual resource dependencies and gives learners additional guidance in their resource exploration and consumption.
The Prerequisites Map provides a stricter relationship between concepts and between resources. Specifically, the Prerequisites Map illustrates the depends-on relationship identified by the Resource Organization Engine, giving learners clear paths from learning the fundamentals of Data Science to applying technical skills and concepts to a practical research task or project. Like the concepts of the DSEO, Prerequisites, both at the concept and resource level, influence recommendations made to the learner.
Resource Personalization Engine (UPCOMING)
The Resource Personalization Engine aims to integrate user data with data generated by the Resource Organization Engine to provide a rich, personalized learner experience on the TCC Web Portal
To accomplish this goal, the Resource Personalization Engine makes recommendations of additional resources based on:
1. Tag or text similarity
2. Other learners’ resource navigation patterns
3. Resources that similar learners found useful (collaborative filtering)
4. Resources that a learner has viewed, completed, rated, or reviewed
5. The prerequisites of a resource for which that a learner has conveyed interest